The Complaint
Tom Kyte, THE resource of just about everything Oracle, said this about Read Uncommitted:
READ UNCOMMITTED . The READ UNCOMMITTED isolation level allows dirty reads. Oracle Database doesn't use dirty reads, nor does it even allow them. The basic goal of a READ UNCOMMITTED isolation level is to provide a standards-based definition that allows for nonblocking reads.
I'm going out on a limb here in disagreeing with someone who is clearly an expert in his field, but I decidedly disagree with Tom. Read Uncommitted isolation level allows for dirty reads - so the basic goal of read uncommitted is to allow for dirty reads, period. By saying its goal is to allow for "nonblocking" reads, only covers the concept of lock acquisition. However, it ignores the ability to see uncommitted data, regardless of what locking or versioning method is being used by the transaction that created the uncommitted data. In other words transaction 'A' can execute under a serialized isolation level and get all the locks that it wants, but another transaction under read uncommitted should still see the uncommitted rows.
So what's my complaint? In the days of both Sql Server and Oracle having row versioning based concurrency, there's almost no reason to allow dirty reads in a production system. However, Oracle's blatant disregard for the ANSI standard here removes an invaluable tool for the developer.
I've always been a fan of the transaction management components in the Microsoft development stack. From MTS, to COM+, to System.Transactions, it's always been very easy to maintain consistency over complex business operations. These days I even wrap my unit tests in transactions so I don't need to create cleanup routines to purge data after a test run. But there is the problem. When trying to debug a set of complex database operations, by default, the transaction keeps me from seeing the current state of the database from an outside connection.
For example, consider the following simplified example inside of a single transaction:
OracleCommand cmd1 = new OracleCommand("insert into batch returning batch_id into :batchId")
OracleCommand cmd2 = new OracleCommand("update table2 set batch=:batchId")
OracleCommand cmd3 = new OracleCommand("select * from table2 where batch=:batchId and Quantity!=OldQuantity")
In my case, cmd3 wasn't returning any rows. What is wrong? How do I find out?
In SQL Server, all i need is a simple "set transaction isolation level read uncommitted" in my query window. From there I could put a breakpoint at cmd3 and execute the same select statement in my query window. Playing around with some variations, I would have discovered that OldQuantity was null so I needed to revise my query slightly. However, there is no equivalent to this in Oracle. There's no way to see the modified data outside of the transaction.
The Work-Around
But what you CAN do is look at the data from within the transaction, here's how.
Create a static method that converts a dataset into a string. Any string is fine, but I choose an HTML method from YordanGeorgiev. You then need another method that takes a command object, executes it, and sends the resulting dataset to your dataset-to-string method. Mine looks like this:
public static string DumpQuery(OracleCommand cmd)
{
OracleDataAdapter da = new OracleDataAdapter(cmd);
DataSet ds = new DataSet();
da.Fill(ds);
return DumpHtmlDs(null, ds);
}
Finally, if your sql statement is more than just a one liner, it'll be a mess to try to modify it in the debugger. I instead created "query.txt" file in c:\temp.
Now put a break point at your equivalent "cmd3" and run to that piece of code.
From here you can run whatever statement you want.
In my case first replaced the CommandText with a new command by reading in my query.txt file with the File.ReadAllText method:
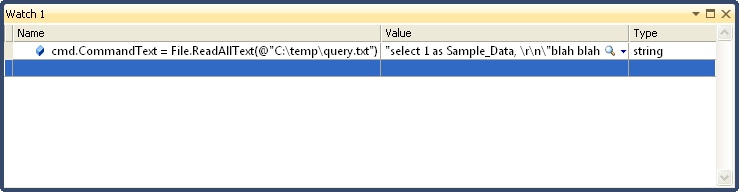
Then you can execute the new command and convert it to text:
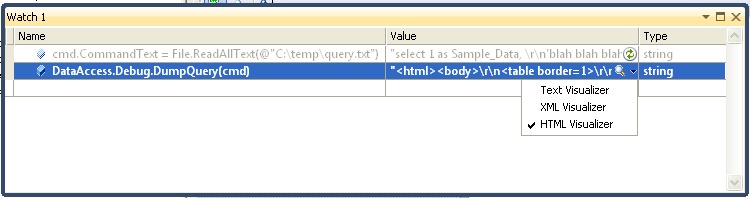
In my case, choosing html as the return format is nice and convenient since I can use the HTML Visualizer:
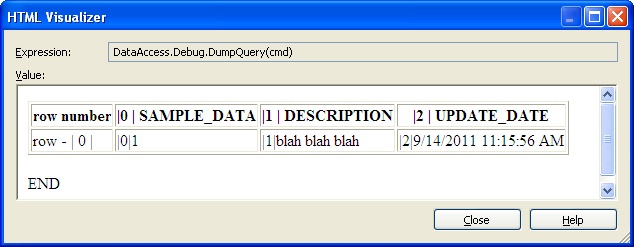
You can continue to update your query.txt file and click the refresh buttons in the watch window to repeat this process and view all the dirty data you'd like. You may want to change the transaction timeout of your outer test transaction to something that gives you plenty of time to play.
This isn't as efficient as using a good query tool, but it's better than nothing. As for Oracle, a company that prides itself on all it's knobs and switches to give you exactly what you need, I'm disappointed in their lack of support for dirty reads and hope they consider some sort of feature in the future.
B